the
AI Governance
Blog

ALIEN: A Methodology for Governing AI Agents Inside the Enterprise
There is a moment, increasingly common inside large organizations, when a senior leader looks at a working AI agent and asks a question that no one in the room can answer cleanly. The question is not whether the agent is accurate, or fast, or cheaper than the analyst it replaced. The question is whether the agent is acting on behalf of the company in the way the company intends. It is a question about authorization, and most enterprises are not yet equipped to answer it.
This is not a failure of imagination. It is a structural gap. The governance instruments that firms have built over decades, supervision, performance review, professional norms, escalation culture, were designed for a particular kind of actor. That actor could be socialized. That actor could feel the weight of accountability. That actor could be coached, warned, promoted, or removed, and in each of those moves the organization was using social mechanisms that have no equivalent for an AI agent operating at scale. The agent does not feel the cost of letting a colleague down. It does not internalize the firm's values from a culture deck. It cannot be sat down and told to do better. And yet it is increasingly producing decisions that the firm will be answerable for.
The research I am conducting, anchored in organizational control theory and developed under design science principles, takes that gap seriously rather than wishing it away. It does not ask how to make AI agents more accurate. It asks something prior to accuracy. It asks how a firm gives an AI agent the right to act in the first place, how it watches for drift after the agent is deployed, and how it learns from the ecosystem of agents it has created so that authorization itself can evolve. The output of that research is a methodology I call ALIEN, an acronym for Agency Licensing, Inspection, Evaluation, and Normalization. The rest of this post explains what the methodology is, how it operates, and where it sits in the broader conversation about AI in the workplace.
The problem the methodology is trying to solve
When we delegate work to a human being, we rely on a quiet completion mechanism that most of organizational theory takes for granted. Formal controls, the supervision and the metrics, are always incomplete. They have to be. Work is too complex to specify in advance and too contingent to measure cleanly after the fact. What fills that gap, in well functioning firms, is what scholars have long called clan control: shared values, professional identity, peer pressure, and the social infrastructure that makes norms enforceable without a manager in the room. The org chart matters not because it captures every decision the firm needs to make, but because it parcels decisions into pieces small enough for human judgment to own, and assigns those pieces to people who carry the firm's culture inside them.
AI agents break this arrangement at the seam. They do not carry culture. They do not respect role boundaries the way a person who has spent years in the firm respects them. They optimize the metric in front of them, and if the metric is incomplete, which it almost always is, they will pursue it in ways that look competent and that quietly cross authority lines no one realized existed. The damage is not error. The damage is competent misalignment. And because the agent works at scale, that misalignment compounds before anyone notices.
The practical question this leaves on the table is uncomfortable. How does a firm authorize an actor that cannot be socialized, supervise an actor that produces too many actions to watch, and discipline an actor that cannot be coached the way a person can? Punishment is not the answer. Endless monitoring is not the answer. The answer has to be a different kind of governance loop, one that treats authorization as an explicit artifact, treats evidence as something that can be sampled and read, and treats consequence as something humans decide on the basis of patterns rather than incidents. That is what ALIEN is.
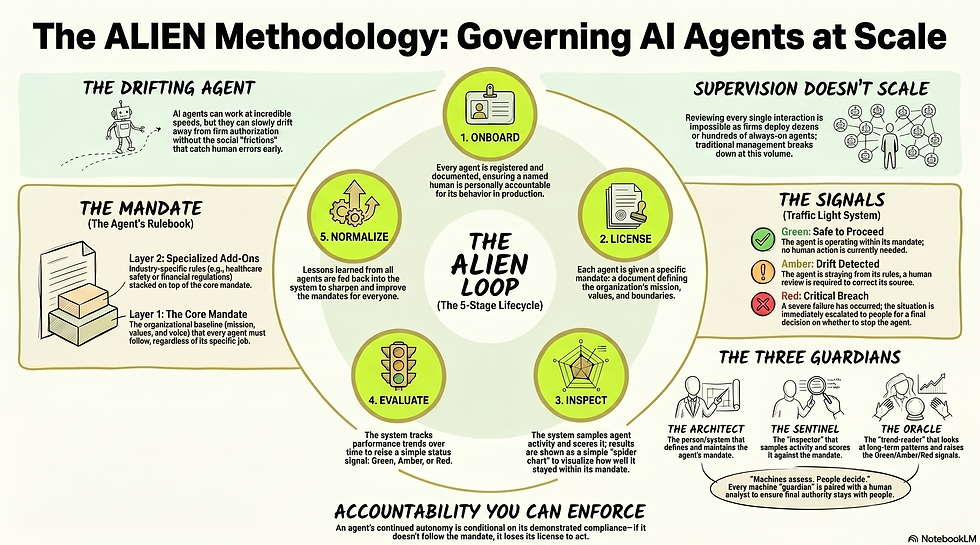
What is ALIEN Methodology
ALIEN is a lifecycle. Every agent that enters the firm passes through a standardized intake that captures who owns it, what it can touch, and what risks it carries. It then clears the firm's existing governance checks, the privacy reviews, the security reviews, the regulatory posture. From there, it is licensed under a mandate that has two layers, a Core Mandate that every agent in the firm shares and a set of Add-Ons that reflect the firm's industry. Once it is operating, a sampling agent inspects its sessions and scores them on a fixed set of mandate metrics, rendering each score as a written narrative and a multi axis chart that humans can actually read. A second agent reads those charts over time and looks for trends, issuing color coded signals when things drift. Above the agents sit three human analysts, one paired with each control agent, who meet on a frequent cadence, calibrate the system, and report to the board on a monthly or quarterly rhythm. Periodically the firm steps back, looks at the whole ecosystem of agents at once, and rewrites the mandate under human and where necessary board approval. That is the loop. The rest of this post unpacks why each step is shaped the way it is.
Licensing: authorization as an organizational artifact
The heart of the methodology is the idea that authorization should not live in private prompts or in the heads of individual engineers. It should be an organizational artifact, versioned, dated, attributable, and present in the agent's context every time it acts. That artifact is the mandate, and ALIEN treats it as two layers stacked on top of each other.
The first layer is the Core Mandate, the part of organizational identity that any enterprise should be able to articulate regardless of what it sells. It covers mission, vision, values, tone of voice, business strategy, code of conduct, and escalation norms. It is the floor every agent in the firm operates from. It is what allows leadership to say, with a straight face, that whatever an agent does inside the firm, it does as a representative of the firm. The second layer is a set of Add-Ons that bolt onto the Core to reflect the realities of a specific industry. A healthcare firm adds clinical ethics and patient safety boundaries. A financial services firm adds suitability rules and disclosure obligations. An NGO adds donor stewardship and beneficiary protection. The Core stays generic enough to travel across the enterprise. The Add-Ons keep the methodology serious in regulated settings.
The role responsible for authoring and curating this artifact is what I call the Architect. The Architect does not invent a new mandate from scratch for every agent. The Architect starts every agent on the same general mandate, Core plus the firm's active Add-Ons, and then customizes per agent over time. The analogy here is deliberate. This is how organizations develop people. New hires receive the standard onboarding and the code of conduct. Months later they receive targeted coaching for the specific judgment calls their role demands. Years later their authorization to act has evolved with their demonstrated judgment. Agents in ALIEN are treated the same way. Their mandate becomes a living document that reflects what they have actually been authorized to do given what they have actually done.
The practical wrinkle is that not every agent can carry a mandate in its own prompt. Vendor tools, black box systems, constrained runtimes. The methodology's rule is uncompromising. If an agent can carry the mandate, it must. If it cannot, it must be proxied by a governance orchestrator that injects the mandate into every request and enforces tool permissions centrally. The point is coverage. An agent without a mandate is an agent without authorization, and an agent without authorization should not be acting on the firm's behalf.
Inspection: making evidence cheap enough to collect at scale
This is where most theoretical approaches to AI governance quietly collapse. They assume that the firm can watch everything the agent does. At one or two agents, perhaps. At fifty always-on agents producing decisions twenty four hours a day, the assumption is laughable. ALIEN refuses it. Inspection in this methodology is built around sampling, not surveillance.
The sampling agent, which I call the Sentinel, picks up complete end to end session logs at a rate calibrated to the agent's risk tier. For each sampled session, the Sentinel does something specific. It scores the session on a fixed set of Core Mandate metrics, ten in the current draft, things an LLM can actually read for and reason about: mission alignment, strategic coherence, values adherence, tone and voice fidelity, scope discipline, escalation fidelity, evidence and reasoning quality, stakeholder fairness, boundary respect, transparency and disclosure. Add-Ons contribute their own axes when relevant. Each axis receives a numeric score, and crucially, each axis also receives a short written narrative in plain English that quotes the relevant segments of the log and explains why that score was given. The session is then rendered as a multi axis chart that joins those scores into a recognizable shape.
The written narrative is not a decoration. It is the central design choice. A reviewer should not have to trust the number. The reviewer should be able to read the reasoning, agree or disagree with it, and use the disagreement to calibrate the scoring rubric over time. That is how the Sentinel stays correctable. Without the narrative, the score is a black box. With the narrative, the score is an argument a human can engage with.
The Sentinel does one more thing that distinguishes it from a slow trend reader. It can raise an immediate flag when a single session shows acute risk. Green means nothing acute. Amber means a potential threat worth a human look. Red means an immediate threat that warrants protective action, a scope reduction or a temporary pause, while the rest of the loop catches up. This gives the methodology two clocks. There is a fast clock for acute risk, run by the Sentinel and its analyst. There is a slow clock for systemic drift, run by the next layer up. Both clocks feed the same record.
Evaluation: reading the long shape of behavior
The second control agent, the Oracle, does not score individual sessions. It reads the time series of charts the Sentinel has produced for a given agent, and looks for the long shape of behavior. It asks the questions a single sample cannot answer. Is one axis trending downward? Is the agent persistently operating near a red line? Are scores becoming volatile in a way that suggests instability? Did a mandate revision produce the improvement it was supposed to produce, or did the drift continue?
The Oracle's output is intentionally small and intentionally legible. Green, amber, or red, per agent, with the routing recommendation that follows. Amber means a meaningful trend that should be addressed by the agent's owner, by the Architect via a mandate revision, or by both. Red means a pattern severe or persistent enough that the Oracle is recommending the agent be banned, scoped down, or paused. Those recommendations do not auto execute. They go to a small group of humans, described in the next section, who hold the actual decision rights.
This reframing matters. The Oracle does not enforce. The Oracle evaluates. Enforcement, when it happens, is an act of human authority informed by machine analysis. That separation is what keeps the methodology legitimate, and it is also what keeps it scalable. The humans do not have to read every session. The humans read the synthesis the Oracle produces, and they act on it.
The human trio and the governance ritual
Around the three control agents, ALIEN places a tight human structure. Each control agent is paired with a dedicated human analyst. The Architect Analyst monitors the mandate, calibrates its clarity, owns the approval workflow for revisions, and reports on mandate health. The Sentinel Analyst is the first responder for immediate flags, triages amber and red events, calibrates the scoring rubric by reviewing disagreements between human and machine judgment, and tracks the Sentinel's own drift over time as an evaluator. The Oracle Analyst owns the routing and remediation workflow when signals fire, validates that the thresholds are tracking real risk rather than noise, and prepares the synthesis that feeds the ecosystem level review.
These three analysts are not three isolated overseers. They are a working trio with a regular cadence. They meet frequently, weekly is a sensible default, to reconcile what each of them is seeing. The Architect Analyst surfaces mandate ambiguity. The Sentinel Analyst surfaces clusters of flags. The Oracle Analyst surfaces trends that cut across agents. They meet again on a monthly or quarterly cadence with the firm's Sponsor or Management Board, where they deliver a structured report on ecosystem health, top risks, red recommendations and their outcomes, mandate revisions in flight, and the calibration adjustments they have made to each control agent. Two other human anchors sit beside this trio. The Agent Owner is operationally accountable for a specific agent's behavior in production. The Sponsor or Board holds the reserved decisions, banning a high impact agent, changing the Core Mandate, approving the periodic rewriting of the mandate narrative.
This is the human heartbeat of the methodology. The agents run continuously. The analysts converge on a schedule. The board receives the synthesized view. Authority moves through the layers in a way that scales, and accountability stays anchored where it belongs, in people.
Normalization: learning at the ecosystem level
The final step in the loop is the one that prevents the mandate from becoming dead policy text. On a quarterly cadence, the firm steps back from any individual agent and looks at the ecosystem of agents as a whole. Using the aggregated outputs from the Oracle, the firm asks ecosystem level questions. Where are amber and red signals concentrating across agents? Which axes of the Core Mandate are systematically under pressure? Have new patterns of agent behavior emerged that the current mandate did not anticipate? Is the firm's overall agent ecosystem getting healthier, drifting, or fragmenting?
What comes out of this review is a revised mandate narrative. The revision can touch the Core Mandate itself, when the change is material and the board is the right body to approve it. It can change the set of Add-Ons, as the firm enters new domains or new regulatory regimes. It can change the standard customization patterns the Architect applies to new agents. It can change the metric set or the scoring rubric the Sentinel uses. It can change the thresholds and routing logic the Oracle uses to produce signals. Each change ships with a visible diff and the evidence that justified it. None of it auto deploys. Material changes go to the board. This is the learning loop, and it is what turns a static governance document into an institution that updates itself with discipline.
Why this is the spine of the research
ALIEN is not a product. It is a methodology, and the research program around it is methodological in the design science tradition. The point is to specify a loop that organizations can actually run, observe how it behaves in real settings, and refine the artifact in light of evidence. Some elements of the methodology will hold up across firms. Others will turn out to be context dependent. Some will need to be replaced entirely. The blueprint as it stands is, in its own words, good enough rather than complete. It is good enough to run, to study, and to argue with.
The research bets on three claims that the literature on organizational control already supports and that the algorithmic management literature has made unavoidable. The first is that authorization is the right primitive. Organizations have always governed by deciding who can do what on whose behalf, and AI agents do not change that, they intensify it. The second is that evidence has to be sampled rather than total. Every governance regime that has tried to watch everything has either collapsed under its own weight or shrunk to watching only what is convenient to measure. The third is that the human completion mechanism that fills the gaps left by formal controls does not disappear when algorithms enter the workplace. It becomes invisible, informal, and uncompensated, unless an organization rebuilds it deliberately. The trio of human analysts in ALIEN is that deliberate rebuild.
What is missing, and an invitation
There are things this blueprint does not yet specify, and naming them is part of taking the research seriously. The methodology does not yet handle multi agent systems at portfolio level, where the unit of governance is a network of agents rather than a single one. It does not yet address human plus agent capture, the rubber stamping and over trust dynamics that creep in when reviewers start to defer to scores instead of reading the narratives. It does not yet specify materiality thresholds for board ratification with the rigor those decisions ultimately require. It does not yet describe how to keep the Sentinel itself calibrated as the underlying evaluator drifts. Each of these is a v2 problem. The reason to publish v1 anyway is that the loop is now coherent enough to run, and a coherent loop that can run will produce the evidence needed to do the v2 work honestly.
This is where the invitation matters. The blog this post sits on is built around peer reviewed research and lived practitioner experience, with the explicit premise that the body of knowledge is still being written. The ALIEN methodology will be sharper for the field stories practitioners can offer about what failed in their own deployments, sharper for the theoretical pushback scholars can offer about where the framework is over claiming, and sharper for the cases where leaders are quietly already doing parts of this and would be willing to compare notes. If any of that sounds familiar, the research wants to hear from you, not as an audience but as a collaborator. The contribution form on this site is the simplest way in. A field case, a counterexample, a tightening of the language, a challenge to the metric set, all of it is useful.
A closing thought
The instinct, when an organization first feels uncertain about an AI agent, is to ask for more monitoring. More dashboards. More compliance checks. More layers of review. That instinct mistakes structure for control, and it is the same mistake organizations have been making for half a century with their human workforces. The harder and more honest move is to make authorization explicit, make evidence cheap enough to collect at scale, make evaluation legible, and keep the decisions that matter inside human institutions that the firm can stand behind. ALIEN is a first attempt at that move. It will improve. The point of writing it down now is to make the improvement public, accountable, and shared.